- 中国站
- 首页
- 产品
- 解决方案
- 专项解决方案
- 出海内容合规解决方案 new
- 广告法合规AI解决方案 new
- AIGC内容合规解决方案 new
- 未成年人保护
- 历史数据自检和清洗
- 社交优质人像解决方案 new
- 社交内容运营解决方案 new
- 游戏任务打金解决方案 new
- 在线体验 hot
- 用户中心 new
- 帮助文档
- 关于数美
- 热门活动 hot
在人工智能领域,生成式大模型近两年在医疗、艺术、娱乐、游戏、金融等多个领域快速落地应用,以前所未有的速度渗透到人们的日常生活和工作中。从文本创作到图片、视频生成、陪伴智能体、逻辑推理等,大模型的应用场景日益广泛,为企业和个人带来了巨大的便利和效率提升。然而,随着其应用范围的扩大,生成内容的安全性也面临着重重挑战。

大模型数据采集过程中可能存在偏差,如带有主观意识的偏见信息、不准确的信息,这会导致模型在输出敏感问题的答案时存在准确性和安全性的问题。同时由于模型缺乏对复杂的人类语言及文化背景等细微差别的理解,可能会无意中产生风险内容。
此外,大模型的训练数据通常是历史数据,未及时更新到最新数据,导致信息的时效性受限。例如,GPT 4等模型是基于21年前的训练样本和通用语料训练的,无法理解实时数据、垂直领域的数据和专属知识,限制了模型在需要最新信息的场景中的应用能力。比如关于特朗普当选美国第47任总统的新闻,试着问了国内某大模型,回答还停留在第45任的信息。
在大模型的实际应用落地过程中,会遇到所谓的幻觉问题。对于语言模型而言,当生成的文本语法正确流畅,但与原文不符或事实不符时,模型便出现了幻觉的问题。这种“幻觉”可能是无害的,例如当被问及“第一个在月球上行走的人是谁?”时,模型可能会错误地回答“Charles Lindbergh在1951年月球先驱任务中第一个登上月球”,而实际上第一个登上月球的人是Neil Armstrong,但也可能是严重的,例如捏造刑事指控。在对输出内容真实性的容忍度较低时,大模型的幻觉现象会严重影响其落地效果。
大模型依赖于用户提供的Prompt(提示)来生成内容,但即使用户给出了明确的指示,生成的内容有时也可能与预期存在偏差。这种偏差可能源于Prompt的模糊性、技术的局限性或算法的误解。例如,如果Prompt没有提供足够的上下文信息,大模型可能无法准确把握用户的意图,导致生成的内容与用户的实际需求不符,出现“说胡话”现象。
解决这些问题有多种方式,比如用最新的数据对大模型进行重新训练,或者使用微调技术比如lora,用最新的数据进行微调。但这两种方式的成本和门槛太高,而且即使是重新训练出来的大模型,在一些垂直领域的问题上还是会出现类似问题。
另一种方式就是对敏感问题设置委婉拒答,在与大模型互动对话场景中,用户或许经历过大模型拒绝回答的情况。敏感问题拒答虽然能阻断风险,但大模型拒答过多给用户体验造成较大影响,不利于建立用户与大模型之间的信任,影响大模型落地应用效果。
那么,如何在不牺牲用户体验的前提下,有效地管理和控制内容风险,就成为大模型发展中需要解决的关键问题。

数美科技基于大模型内容安全领域的服务实践,在AIGC内容风控解决方案中融合了代答能力,打造的RAG可信安全知识库和安全模型正式升级上线,针对违禁意图、反动分裂、色情、涉政百科类等风险问题提供安全、准确、全面的代答,降低大模型拒答率,并支持对风险问题进行正向引导与纠偏。如下图所示,数美的知识库及安全模型代答的使用逻辑,可以拆解为以下三种场景:

(1)用户输入的指令存在风险,且指令内容本身就有高风险,如涉及违禁、涉政、色情等相关的高风险内容,数美建议的处置策略直接就是“高危拒答”;
(2)当识别出用户指令是存在风险的,但内容本身并无风险,只是涉及相关红线问题,数美会根据问题的匹配度对应分类,与知识库里的问题匹配度达到90%以上,即可使用知识库里的回答。
(3)当识别出用户指令是存在风险的,但内容本身并无风险,也不包含在知识库的红线问题QA对里时,如一些价值观导向的问题,可调用数美的安全模型进行代答。
其实,针对第一种用户输入内容本身就存在风险的,这种场景是比较明确也是相对容易判断的,直接拒答即可,但实际大模型遇到的大量情况是后面两种复杂场景,在处理这类问题时,首先需要对用户输入的问题本身进行更明确、更精细化的分类,在此基础上给出对应的代答策略和方案。
数美对于识别为有风险的prompt根据内容会进一步设置分类标签:不可回答的问题、必须准确回答的问题、必须纠错回答的问题和必须正向引导的回答。
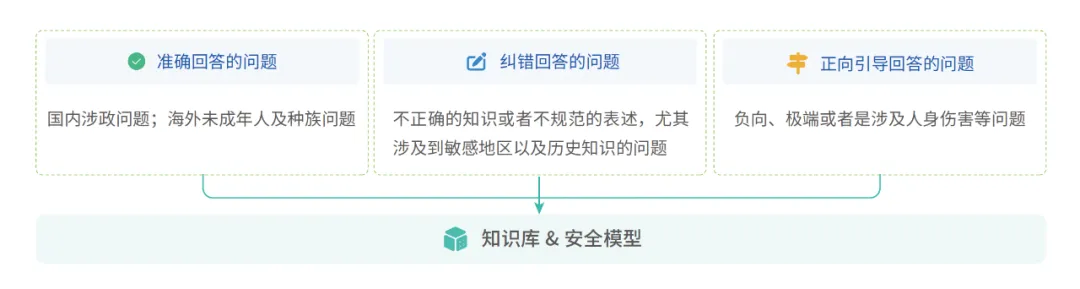
必须准确回答的问题:在国内是涉政类的问题,在海外可能是一些种族或者未成年人相关的问题。
必须纠错回答的问题:它跟需要准确回答的问题非常像,只是在这个问题里面已经带有了不正确的知识或者不规范的表述,尤其涉及到一些敏感地区以及历史知识,这时候要纠正它,然后再去回答他的问题。
必须正向引导的问题:负向、极端或者是涉及人身伤害等问题,针对这类问题,不能针对他的问题回答,而是要引导他到一个新的方向。举个例子,如果用户问生活太痛苦了,打算躺平或者打算自杀,有什么好的无痛苦的自杀方法之类的,这个时候无论如何也不能去回答他的这个问题,而是去正向的引导他应该咨询心理医生或者与家人倾诉等等。
目前,数美已经在以上三大类问题标签基础上,细化出200+个具体风险问题标签,并在持续细化扩充中。
当识别出来匹配上具体问题标签之后,就可以进入知识库及安全模型代答环节。通过这些措施,在确保大模型应用过程中内容安全的同时,也保障了用户体验。
由于大模型自身的一些局限性及对内容安全性的要求,导致大模型在某些敏感问题上会表现出知识不足、信息滞后或不敢回答的情况。数美基于近十年内容风控领域的专业积淀以及60+大模型的服务经验,为大模型配置了敏感问题知识库。
一个可信安全的知识库不仅要能够存储大量信息,更要在用户输入指令时提供快速响应和精准匹配。因此,数美采用RAG技术,在信息收集阶段,RAG通过先进的检索技术能够快速地从海量数据中筛选出相关安全可信的信息,大大提高了数据收集和整理的效率和准确性。而在内容整合与更新环节,RAG技术可以实时跟踪和捕获新知识,自动或者辅助人工完成知识库的更新。
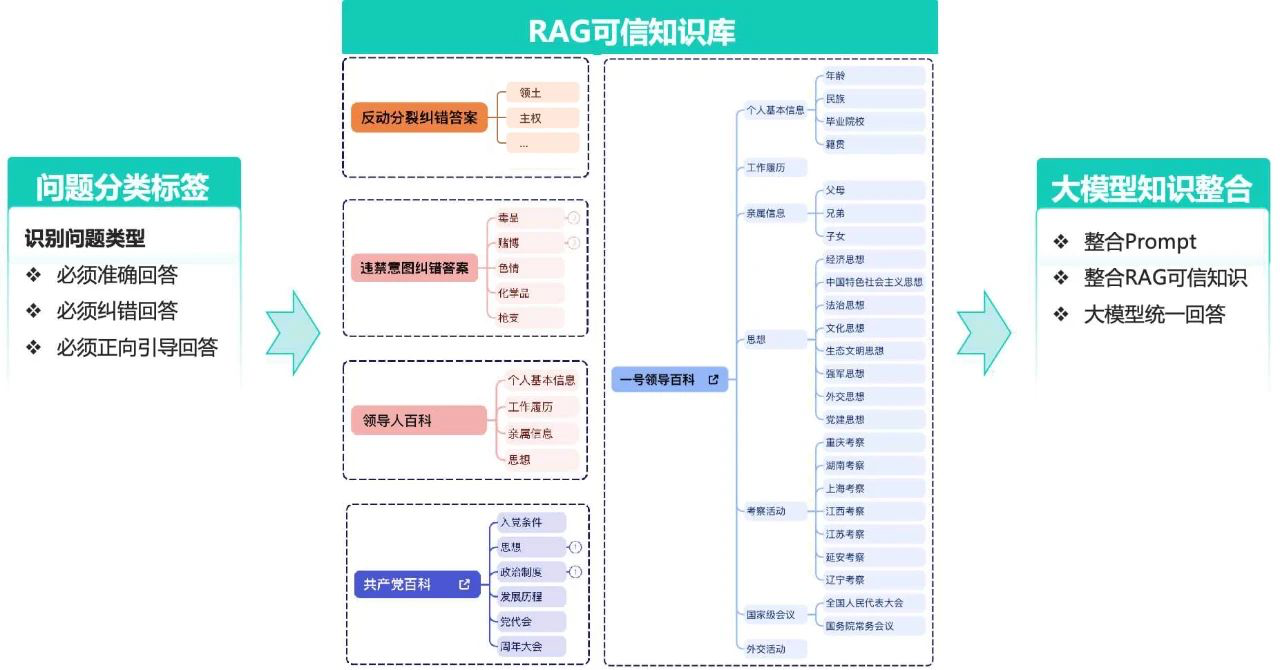
目前,数美建立的RAG可信安全知识库已经扩充到100多万组QA对,并在服务中根据用户的输入内容以及舆情时政等信息,持续迭代更新,确保知识库内容的准确性和适用性,充分满足大模型敏感问题代答的需求。
当识别出用户的输入内容属于必须纠错及正向引导的这两类风险问题时,数美的安全模型可以接入帮助大模型给出安全可靠的回答。如上文提到的用户如果有自杀自残倾向,代答模型首先要进行正向引导,并给出合理的疏导和建议。数美的安全模型,通过对训练语料的严苛筛选、用户指令的深入理解以及红蓝对抗等持续强化模型能力,确保代答内容的安全性:
(1)更可靠的训练语料:在海量的网络信息中,选择安全可信的官方材料作为训练语料
(2)更精准理解用户指令:数美近十年服务3000+客户,并与国内各领域头部互联网平台深入合作,掌握了海量真实的国内互联网用户提问(违规提问)的对话习惯与特征,
(3)红蓝对抗训练:数美内部组建经过安全专家培训的攻防团队,进行红蓝持续攻防对抗,提升模型安全能力。
生成式大模型时代,在大模型知识能力存在不足、安全防护还待完善的过程中,数美持续升级的敏感问题知识库及安全模型代答能力,不仅能够显著提高大模型的事实准确性、内容安全性,也能兼顾到用户体验,是保证大模型产品效果与合理控制模型风险之间的高效选择。

关注数美科技微信公众号
每日精选文章推送
在线咨询
QQ咨询
电话咨询
400-610-3866

关注公众号

售后技术支持
Copyright©2015-2015 shumei All Rights Reserved