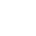涉政语音检测
精准识别各类场景中涉政人物、政治事件、反动分裂、恐怖主义等百余种类型涉政语音内容
精准识别各类场景中涉政人物、政治事件、反动分裂、恐怖主义等百余种类型涉政语音内容
率先启用NAR模型,构建混合深度神经网络模型,精准识别复杂场景下的标准国歌与歪唱国歌
精准识别音频中含有色情、低俗、污秽、语爱等涉黄语音内容
基于Bi-GRU、Attention模型,精准识别声音中含有娇喘、呻吟、耳骚、喊麦等违规语音内容
精准识别音频各类场景中含有的毒品,赌博,违禁品,违禁行为等违规语音内容
精准识别各类场景中含有污辱、谩骂、诋毁等辱骂语音内容
精准识别利用微信号、手机号、QQ等发布违法垃圾广告和竞品导流语音内容
有效识别各类音频场景中,以英文等其他语种形式出现的涉黄、涉政、辱骂、广告等违规语音内容
有效识别音频中是否出现的维语、藏语、蒙古语、朝鲜语等多种民族语言,以满足企业不同的运营需求。
仅支持企业用户咨询,不支持个人业务
![]()
将音频文件拖拽此处,或本地上传
音频文件格式支持:wav、mp3、amr、m4a、wma、ape、ogg。大小限制<50M,时长<10分钟
1. 以上仅为产品体验的部分功能,如需要全功能深度体验,请申请:免费试用
2. 以上检测结果默认按照比较严格的策略进行检测,如需定制策略,请与我们联系:400-610-3866
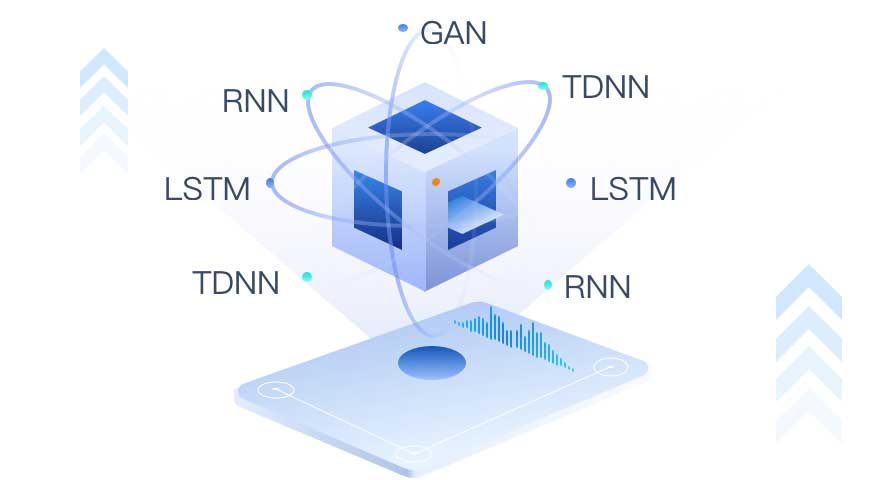
深度融合GAN、TDNN、LSTM、RNN等模型,避免单一模型的天然缺陷,打造复合型高效模型体系
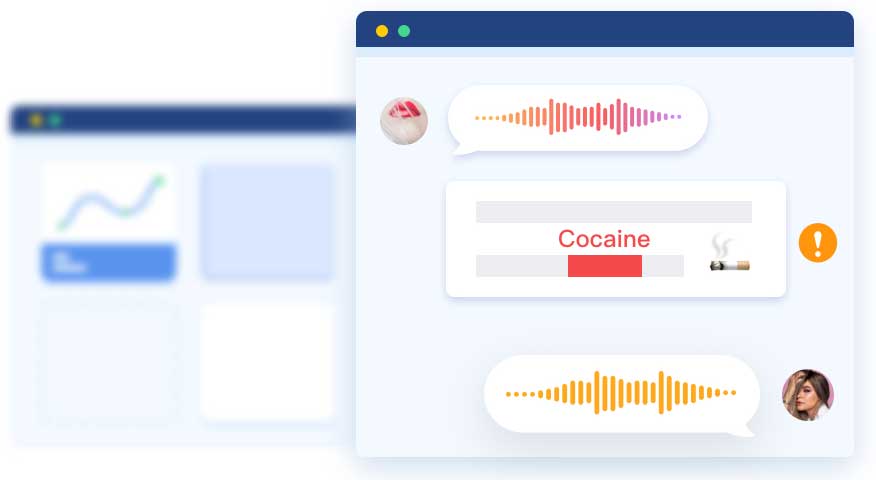
支持多语种识别,能精准辨别以英文等其他语种形式出现的违规语音
除识别违规内容之外,全面覆盖娇喘、呻吟等特殊声音以及声纹、音色的识别需求

1000+三级内容标签体系,深入不同行业审核场景,提供高效、精细、全面的个性化内容审核方案
关联用户行为多维检测,针对高频违规行为可进行账号级的识别和标注处理
全球多集群部署,秒级弹性扩容,每日承载数十亿级海量识别请求
舆情态势实时追踪结合case分析驱动优化,增量模型小时级更新,时刻迭代升级






电话咨询
微信咨询
在线咨询