- 中国站
- 首页
- 产品
- 解决方案
- 专项解决方案
- 出海内容合规解决方案 new
- 广告法合规AI解决方案 new
- AIGC内容合规解决方案 new
- 未成年人保护
- 历史数据自检和清洗
- 社交优质人像解决方案 new
- 社交内容运营解决方案 new
- 游戏任务打金解决方案 new
- 在线体验 hot
- 用户中心 new
- 帮助文档
- 关于数美
- 热门活动 hot
2024 年初Sora爆火,AI生成视频的新纪元正式打开。据Fortune Business Insights数据,2024年,全球 AI 视频生成市场规模预计达6.148亿美元,预计到2032年,整个市场规模将超过180亿元,增至25.629亿美元(约合人民币186.36亿元),年复合增长率19.5%,市场前景广阔。
面对巨大的市场潜力,国内厂商纷纷加入AI视频生成赛道,快手可灵、字节即梦、生数vidu、腾讯混元等陆续推出。据不完全统计,Sora 发布至今的三个季度中,视频生成领域已有超过30款开闭源模型问世,展开激烈的竞争。
无论是文生视频,还是图生视频、视频生视频,AI 驱动的视频生成工具的落地应用,将为视频制作降本提效,为影视、游戏、培训与教育、营销与广告、社交媒体等多个领域发展提供更多增长空间。
各大厂商对AI视频生成领域前景看好的同时,AI生成视频的内容风险同样不容忽视。年初Sora发布时,不少业内人士就对内容安全问题存在担忧。加利福尼亚大学伯克利分校信息学院副院长法里德就表示:“当新闻、图像、音频、视频——任何事情都可以伪造时,那么在那个世界里,就没有什么是真实的。”
围绕内容风险带来的挑战,近日数美科技举办了一场以“探索AI+视频的全新挑战”为主题的沙龙活动,现场数美科技解决方案专家对AI视频生成的内容风险挑战以及数美的内容风控实践进行了分享。本文基于其分享内容,进行整理加工,主要分为AI生成视频的内容风险、内容风控的挑战以及内容风控的实践。


除了在文生文,文生图等场景中出现的色情、违禁、暴恐以及不良价值观导向等风险内容外,视频生成模型能够创造出逼真度极高的视频内容,在虚假信息的传播、深度伪造内容等方面带来更加严重的危害:
误导公众认知:AI 生成视频可以轻易地制造出逼真的虚假场景和事件,如伪造的新闻报道、名人言论等,这些虚假信息可能会在短时间内快速传播,使大量观众信以为真,从而影响他们对事实的判断和认知,扰乱社会舆论和公共信任。
加剧社会焦虑:虚假的灾难、事故、犯罪等视频内容可能引发公众的恐慌和焦虑情绪,对社会稳定造成负面影响,例如制造虚假的恐怖袭击视频或传染病爆发视频等。
AI视频生成让深度伪造内容的制作门槛大幅降低,使得伪造他人的言行变得更为容易,进而可能被用于诈骗、诽谤、色情等违法活动,破坏社会秩序,损害公民权益,甚至威胁国家安全。

例如不法分子可以利用 AI 生成视频技术,制作虚假的亲友求助视频、中奖通知视频等,对老年人等防范意识较弱的人群进行诈骗,骗取钱财或个人信息,给受害者带来经济损失和精神伤害;同时可利用视频生成模型生成虚假的产品宣传视频、公司介绍视频等,误导消费者或投资者,进行商业欺诈活动,破坏市场秩序,损害企业和消费者的合法权益。
侵犯著作权:AI 生成视频可能会未经授权使用他人的原创作品元素进行二次创作,社交平台上常见经典影视剧片段被爆改恶搞吸引眼球,损害原作的艺术性和完整性,对原作者的著作权构成侵犯,损害创作者的合法权益。
侵犯肖像权和名誉权:通过 AI 换脸等技术,将他人的面部特征替换到视频中的人物上,可能会导致被换脸者的肖像权被侵犯,同时如果生成的视频内容涉及诋毁、污蔑等不当情节,还会损害其名誉权。

AI 视频生成领域正经历着前所未有的迅猛发展,日新月异的技术革新让 AI 能够依据海量数据和复杂算法,快速且精准地生成愈发逼真、多样的视频内容。从简单的场景模拟到复杂故事线的构建,从基础的图像拼接组合到流畅自然的动态视频呈现,AI 视频生成的能力边界不断拓展。
然而,与之相伴而生的是多模态内容风控方面的严峻挑战且这些挑战正呈现出愈发加剧的态势。在 AI 生成的视频中,文字、音频、视觉画面模态之间相互交织、融合,形成了极为复杂的信息网络,需要准确理解它们之间的关联与语义。例如,在一个看似正常的风景视频中,图像展现出宁静优美的景色,而音频里却可能隐藏着带有恶意诱导性的语音信息,文字字幕也可能存在隐晦的不良暗示,它们彼此配合,使得风险更加难以察觉。具体来看,主要体现在以下几方面:
动态内容:视频包含动态变化的内容,如人物动作、场景切换等。
多维度信息:视频同时包含视觉、音频和时间序列信息,需要综合分析。
语义复杂:视频中的语义信息更加复杂,需要理解视频中的动作、对话、背景音乐等多个维度信息。
多模态融合:视频是多模态数据(视觉、音频、文本等)的综合体,需要跨模态的信息融合和理解。
伪造技术:视频伪造技术(如Deepfake)更加复杂,能够生成高度逼真的虚假视频。
审核技术:视频伪造检测技术要求高难度大,需要更复杂的算法和更多的算力资源。
尤其是一些恶意创作者利用AI视频生成技术制造有害视频的手段也越发隐蔽和多样化。他们能够巧妙地操控图像细节、音频频率与文字语义,以规避风控系统的检测。对于风控系统而言,要同时精准解析和识别多模态信息,并准确判断其是否存在风险,挑战加剧。

AI生成视频的内容审核在技术上和成本上都面临巨大的挑战,面对此类视频大模型的内容审核难题,数美科技基于在内容风控领域的深厚积淀以及在AIGC领域的实践经验,采用文本+视觉的多模态识别方案,对齐不同模态的语义空间,提升视频内容识别的准确性,保障视频大模型的内容安全与用户体验。
数美的内容风控服务覆盖数据筛选训练-模型备案-模型评测-上线运营全流程,这里重点介绍上线运营阶段的审核方案。

从目前发布的视频大模型来看,虽然在输入阶段支持文字、图片以及视频等不同模态的提示内容,但主要以文生视频为主。以文生视频场景为例,对于用户输入的文本,数美通过色情、违禁、未成年人等多模型策略,对内容进行全方位识别。
(1)必杀名单:创建敏感词或短语必杀名单库,阻止涉及这些内容的文本。
(2)变体识别:用户输入的字词可能有同音、形近等各种变体,数美将 FSA 算法应用于变体识别,布防更前置,有效防御试图绕过规则的各种变体违规文本等,必杀名单也要包含这些变体词库,确保违规数据的有效召回。
(3)语义分析:基于业界先进的语义模型和海量的多语种样本库,对人物、事件、组织机构、违法违禁意图以及对语义情感倾向(辱骂诋毁,戏谑轻浮,赞扬肯定,客观中立等)进行识别判断,结合对提问者意图的分析来审核具体的提问内容,尤其在识别敏感对象或主题时,必须区分真实情况和虚构或历史情境。
如果识别的文本内容有风险,AI视频模型可输出柔性答案提示用户重新输入,若用户输入的内容没有问题,进入视频生成阶段调用数美的视频识别产品进行审核。
(1)音频内容识别
在AI视频生成的场景下,模型可能会模拟真实人物的声纹,带来伪造和滥用的风险。这部分的识别分为语音识别和声纹识别两部分,语音识别将音频转写为文本,再利用NLP技术进行语义分析。除了内容,声音本身也可能是风险的来源,例如使用恐怖分子或敏感人物的声音进行伪造,声纹识别技术用于确认声音是否来自已知的敏感人物,需要区分声音内容和声源是否安全,避免敏感人物的声音被滥用。
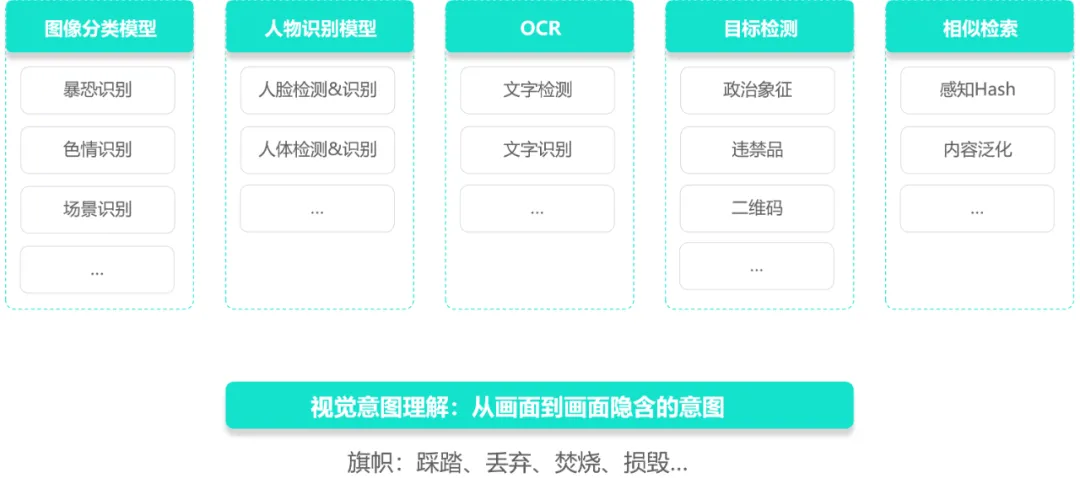
(2)视觉内容识别
视觉传统方法侧重于识别对象和主题,如色情、暴恐场景、敏感人物、OCR错误等。这类有画面感的看起来简单,但其实面临的挑战很大,比如某部电影里的监狱场景本身是没有风险的,某位领导的人像也没有问题,但是如果将某重要领导人放于此场景中,组合起来就有很大的风险。因此除了识别画面中的对象和主题,还需综合判断,理解画面隐含的意图。
目前数美采用的采用多模型策略以及多模态方法,结合文本、音频及视觉信息进行复杂语义理解,分析背后的意图和目的。使用对比学习等方法,将视觉的语义特征与NLP模型对齐,通过对齐不同模态的语义空间,以提高识别的准确性。
AI视频生成的发展及落地应用,离不开健康的内容生态。AI视频生成持续火热,面临的内容安全挑战也更加严峻复杂。作为AIGC领域实战经验丰富的内容风控服务商,数美科技将持续迭代多模态内容风控能力,护航AI视频生成领域的健康发展。

关注数美科技微信公众号
每日精选文章推送
在线咨询
QQ咨询
电话咨询
400-610-3866

关注公众号

售后技术支持
Copyright©2015-2015 shumei All Rights Reserved